文字区域检测和译文回填
ImageTrans实现了一套文字区域检测和译文回填方法。
文字区域检测
ImageTrans支持四种文字检测方式:OCR提供的检测功能、基于深度学习目标检测的气泡检测功能、基于规则的启发式检测方法和自然场景文字检测方法。更多可以看这篇博客:为图片翻译选择合适的文字检测方法。
这里主要介绍启发式和自然场景文字检测方法。
启发式
启发式方法能够较为精确地生成文字区域,并提供详细的参数设置,可以针对不同漫画调整以取得期望的结果。
操作方法:
点击编辑-自动定位文字(启发式),将获得所有候选文字区域
点击编辑-文字区域操作-获取文字区域置信度,文字区域可能性较低的区域的文本框颜色将变为黄色。这类区域可以自行去除或者隐藏,但因为有些区域被误识别为非文字区域,去除的话翻译时还要手动框选,建议不要直接去除。
选择文字区域进行OCR和翻译,操作结束后,可以点击编辑-文字区域操作去除没有原文或者没有译文的区域。

OCR等操作会自动略过文字区域可能性较低的区域。
因为不同的漫画尺寸不同,需要设置不同的文字区域检测参数,可以在项目-设置-文字区域检测里进行设置。
文字区域检测的算法细节见此:基于规则的漫画文字检测方法。
文字区域置信度获取是利用TensorFlow提供的脚本基于卷积神经网络预训练模型重新训练的,相关代码见此:https://github.com/xulihang/text-image-classifier。
文字区域检测的操作本工具提供手动分步操作功能,操作方式是菜单栏-编辑-文字区域操作以及右侧编辑区的合并上下区域和合并左右区域按钮。
自然场景文字检测
自然场景文字检测功能允许用户调用DB、EAST、CRAFT等开源自然场景文字检测方法,这类方法的准确率较高,并能检测倾斜文本,但一般需要花费较长的运行时间。
译文回填
译文回填分为两步:原文抹除和译文的放置。
原文抹除
原文抹除有两种模式,一种是精确模式,一种是非精确模式。
精确模式下,会先生成文字掩膜,再根据掩膜进行背景还原。背景还原方式有两种,一种是使用图像修复方法,一种是用背景颜色生成文字掩膜以覆盖文字。如果掩膜生成不正确,可以使用编辑-生成/编辑掩膜进行修改,掩膜图像会保存在图片目录,带有mask后缀,而去除文字的图像则带有text-removed后缀。
注意:
如果掩膜没有手动生成,每次查看翻译版本时会自动生成,会耗费时间进行计算。
浅色字体区域需要先设置背景颜色和文字颜色或者勾选项目设置里的相关选项,这样程序会判断文字颜色是不是比背景颜色浅,如果较浅,则会对图像做颜色反转,文字掩膜才能够正确生成。
非精确模式下,则会使用背景颜色生成一个文本框进行遮盖,如果该文本框尚没有设置原文和译文,颜色会变成半透明。这一模式较适合背景单一的数字图像。
下图是掩膜编辑器和去除文字器,能用于调整掩膜和文字去除结果:
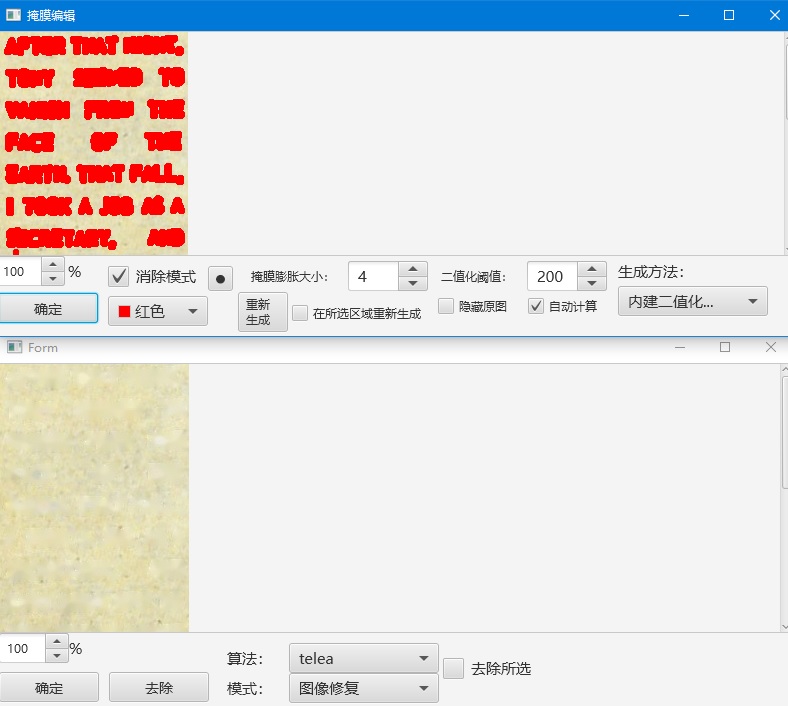
掩膜生成和图像修复支持调用插件以使用第三方的方法,现有的插件是Sickzil-machine和Lama。
其它情况:
如果存在无文字原图,可以通过无文字原图和纯文字图管理器设置无文字原图,查看翻译时会直接使用原图。
更多可以看这篇博客:ImageTrans图片文字抹除详解。
译文放置
根据文本框的大小和位置放置译文,支持自动根据文本框的大小调整译文大小,可以在项目设置里进行设置。
颜色检测
本工具能较粗略地自动检测背景颜色和文字颜色,点击编辑-颜色操作进行相关操作。
旋转检测
本工具支持检测旋转的文字的角度,可以通过编辑-文字区域操作菜单或者自定义工作流进行操作。