快速入门
软件安装
完整版
Windows完整版解压到任意目录后运行ImageTrans.exe即可,Mac完整版打开dmg文件安装ImageTrans到应用目录即可。
跨平台版
下载zip压缩包,解压到任意目录,双击ImageTrans.jar或者命令行输入java -jar ImageTrans.jar即可运行。
软件依赖JRE 11以上运行环境,请先下载安装。下载地址:Liberica JRE 11.0.19 full version
软件依赖OpenCV,请根据系统下载运行库文件,解压后放在ImageTrans的目录下。下载地址:GitHub
OCR与机器翻译的配置
本工具集成了常见的在线OCR和机器翻译服务。一般这些服务均需要设置API密钥才能使用。ImageTrans内置了部分服务的API密钥,可以直接使用:
OCR: 百度、OCRSPACE、Azure
机器翻译: 百度、腾讯、云译、mymemory、DeepL免密钥版
另外也支持若干离线OCR和机器翻译。
离线OCR:
Tesseract
需要使用Tesseract进行OCR的话请自行下载安装(地址),并在ImageTrans里指定Tesseract的路径。
这里再提供一个Windows的安装版本:UB-Mannheim Tesseract5。
Windows10自带OCR
Windows10自带OCR功能,但需要先安装所需语言。它和Azure、OCRSPACE的引擎其实是同一个。ImageTrans中这一OCR引擎的名字叫做WinRT,因为它是基于Windows的Windows Runtime API。
mangaOCR
该OCR能十分准确地识别日漫的文字。安装说明见此:https://github.com/xulihang/ImageTrans_plugins/tree/master/mangaOCR。
macOCR
macOS版本10.15以上系统自带的OCR。使用说明见此:https://github.com/xulihang/ImageTrans-docs/issues/341。
ABBYY
支持调用ABBYY FineReader进行OCR,需要在偏好设置里指定软件的FineCMD.exe的路径。
PaddleOCR、EasyOCR
需要自行安装Python和上述软件,并用提供的server脚本运行,例如PaddleOCR的Server。
离线机器翻译:
OPUS-CAT。OPUS-CAT是芬兰赫尔辛基自然语言处理小组的离线机器翻译引擎,到官网下载安装后使用OPUS-CAT机器翻译插件调用。
eztrans xp。这是一个日韩翻译软件。使用方法见issue29。
验证登录
运行ImageTrans时,会显示验证器,需要填入购买时填写的email和订单号。订单号可以在订单页面中找到。
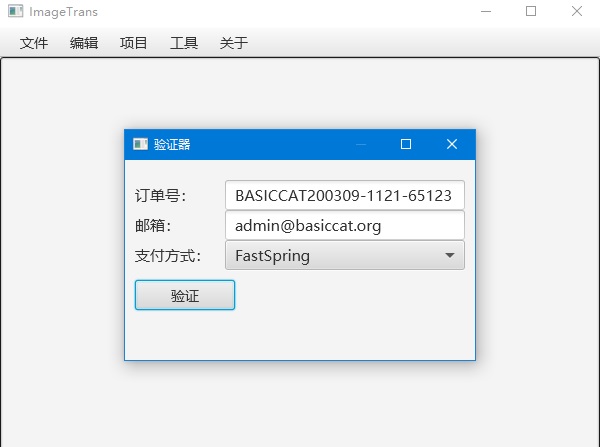
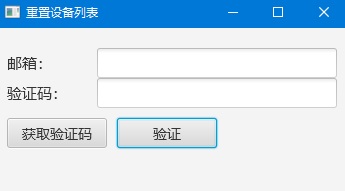
一个email可以在三台设备上使用,要更换设备则需要使用邮箱进行重置。
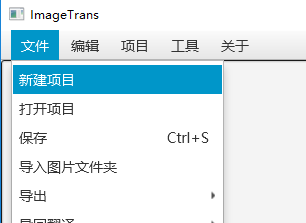
新建项目
菜单栏点击文件-新建项目,选择一个位置并输入项目文件名以保存。
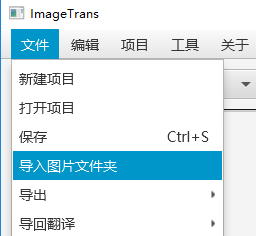
添加图片
菜单栏点击文件-导入图片文件夹,选择图片存在的位置。该操作会读取该文件夹下所有的子目录并导入存在的jpg、png文件。
或者用右键菜单-粘贴图片的方式添加单张图片。
此外亦能导入PDF文件,并提取可复制的文字。
文字转录
工具支持框选文字区域并识别。提供手动框选和四种自动框选,并支持精细调整文本框。
手动框选文字
在图片上双击建立选择框,点住中间区域进行移动,点住右下角调整大小。
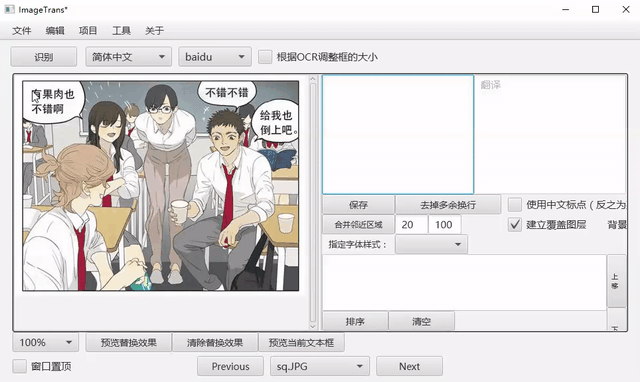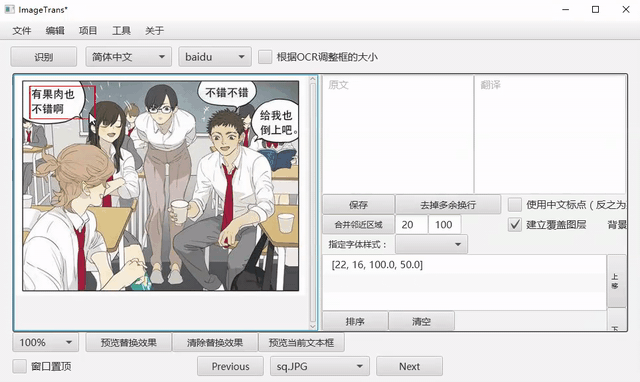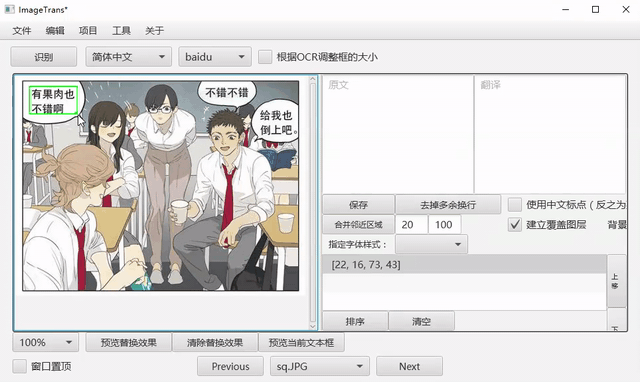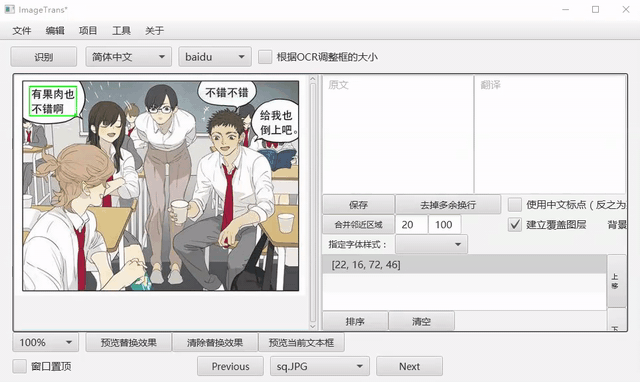
或者点击左侧工具栏的快速框选按钮,可以直接滑动建框。

OCR
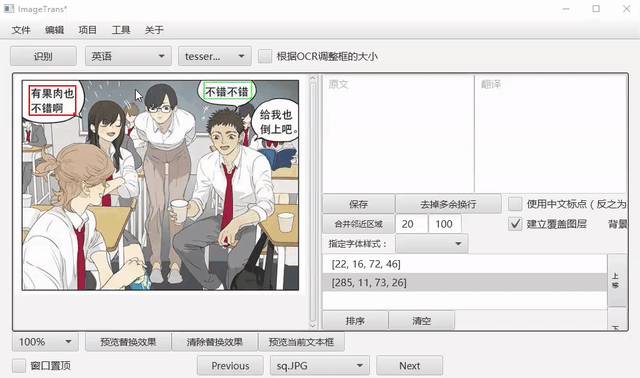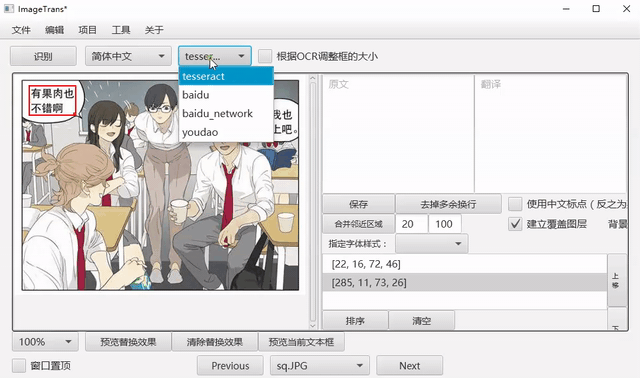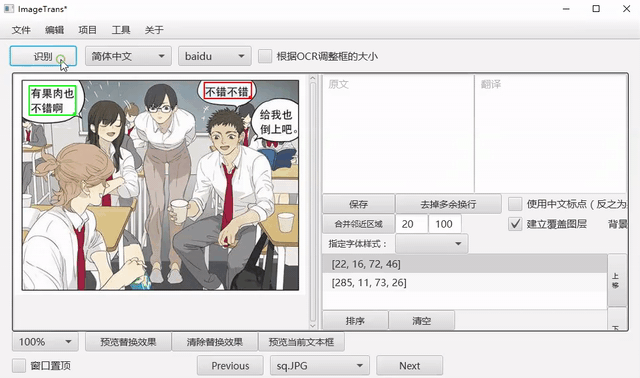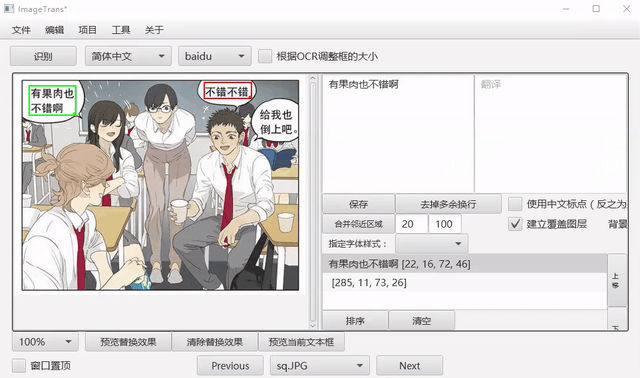
选中文字区域,选择语言和OCR引擎,点击识别进行OCR。
自动识别文字
选择语言和OCR引擎,点击菜单-编辑-自动识别文字,可以自动检测文字区域并转录。其中有道和谷歌是按段落识别,其它引擎是按行识别,可以通过右侧编辑区域的合并左右区域和合并上下区域进行合并。
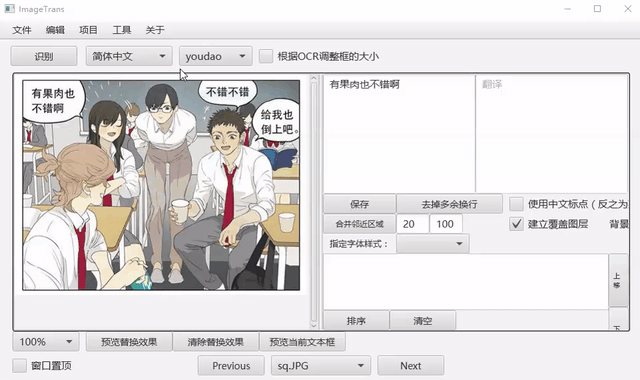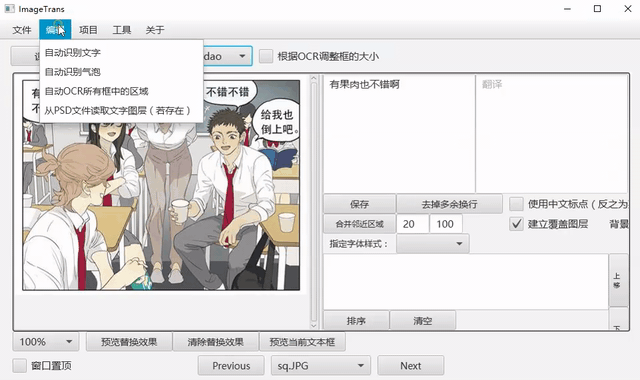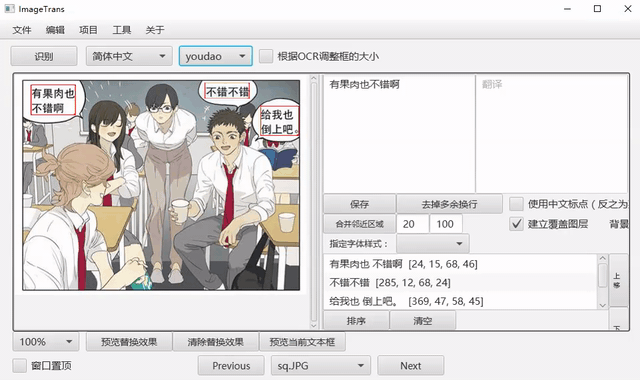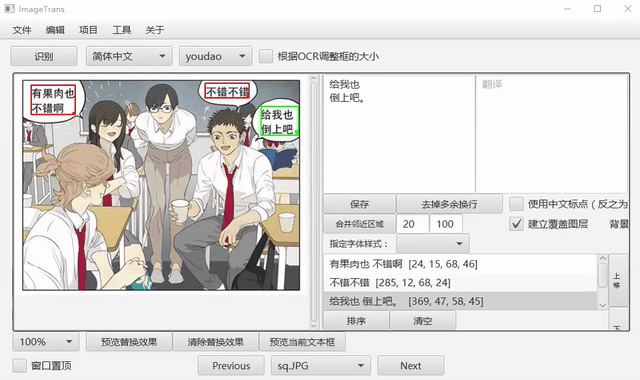
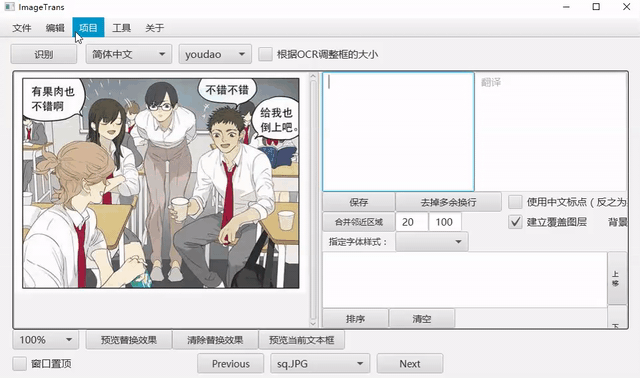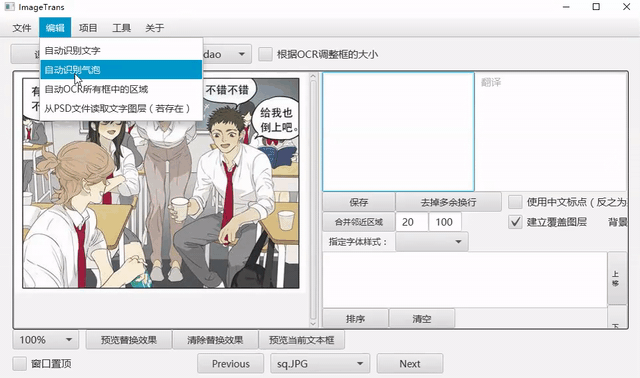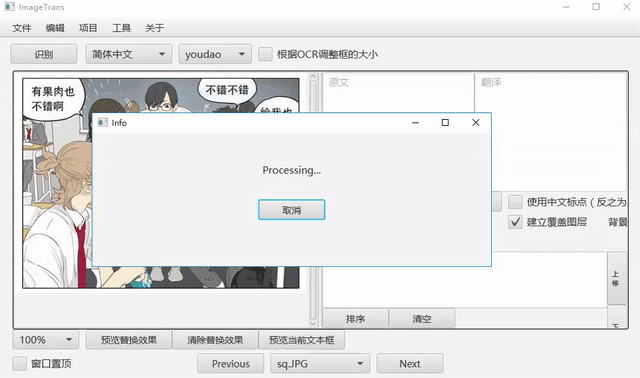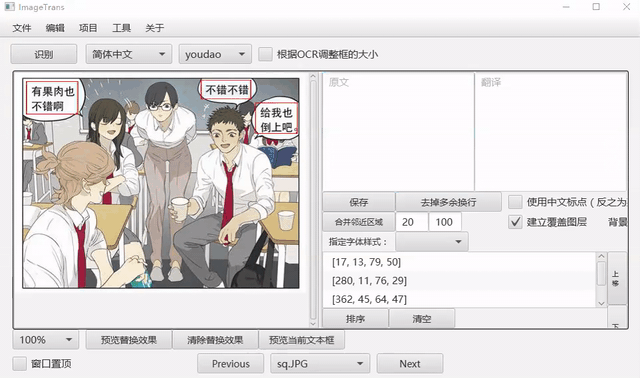
自动识别气泡
点击菜单-编辑-自动识别气泡,可以自动识别气泡。默认使用百度的在线气泡检测服务,可以自行配置离线气泡检测,详见气泡检测。
另提供较为复杂的启发式和自然场景文字检测方法,详见文字区域检测。
自动OCR所有区域
我们可以先把文字区域框出,然后批量进行OCR。点击菜单-编辑-自动OCR所有区域进行操作。
排序
支持根据坐标信息对文字区域进行排序。
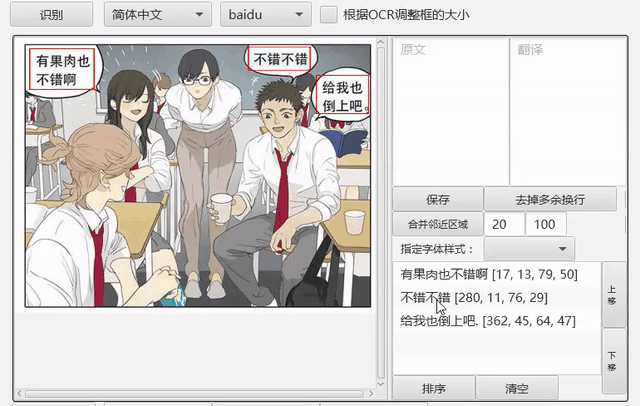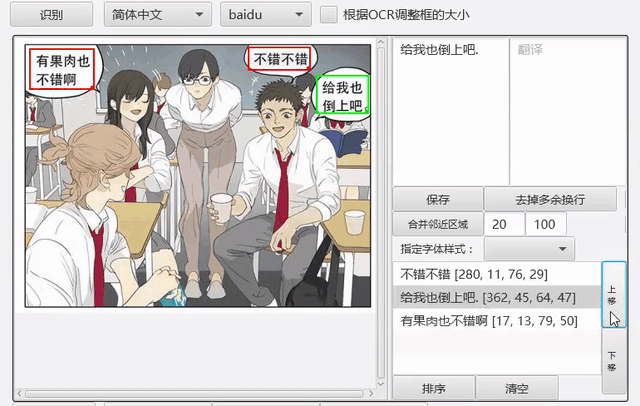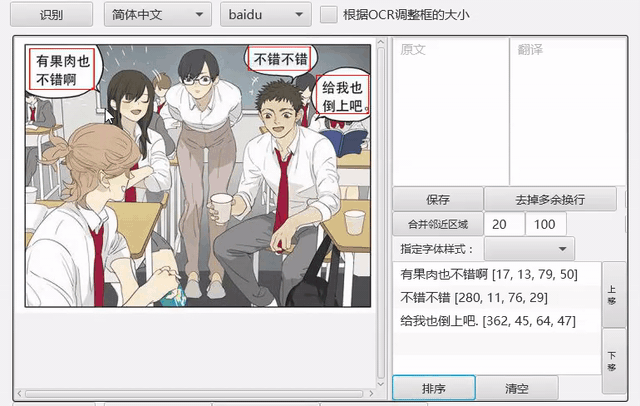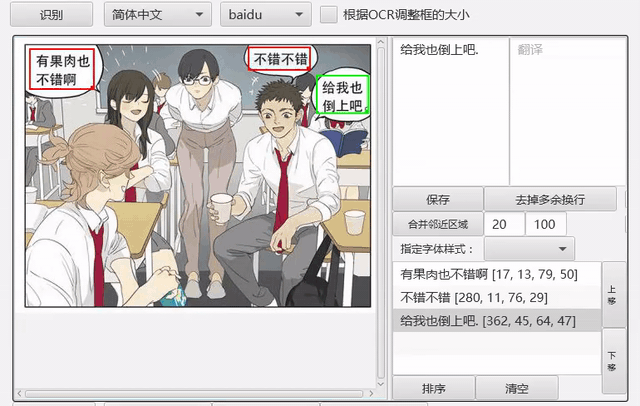
另外针对漫画,提供分镜检测功能,可以在分镜的基础上进行排序,详见issue147。
导出
导出有多种选项。
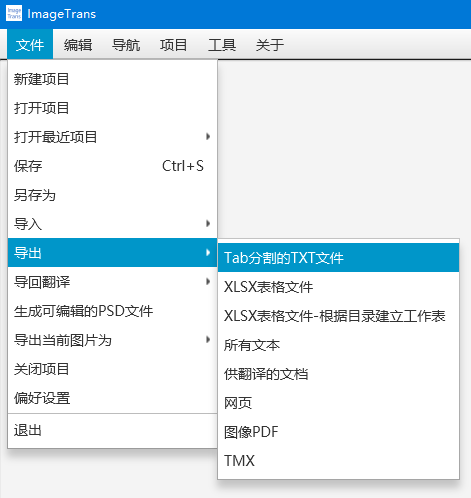
Tab分割的TXT文档,包含坐标信息、字体样式、文字等信息
XLSX表格,和TXT的内容一样
XLSX表格-根据目录建立工作表,按子目录保存图片名、原文和译文信息
所有文本,按每张图片生成包含图片文字的txt文档
供翻译的文档,将原文和译文信息以表格的形式导出为一个docx、txt或者XLIFF文件
网页,将项目导出为网页,可供局域网内的手机阅读,支持语音朗读和按分镜阅读
图像PDF,将项目导出为PDF,支持添加可搜索的文字层
TMX,导出原文译文为翻译记忆文件
分镜,导出分镜图像为单张图片、条漫或者PDF
翻译
在译文区域输入译文并点击保存可以完成一个文字区域的翻译。
可以将翻译导出为docx、txt或者XLIFF文档供外部人员翻译,之后再通过菜单-导回翻译进行导回。
计算机辅助翻译软件BasicCAT支持直接操作ImageTrans的项目文件进行翻译。
翻译记忆、机器翻译和术语管理
切换右侧的操作区到辅助翻译页面,可以使用翻译记忆、机器翻译和术语管理这三个功能。机器翻译需要在偏好设置里设置API,并进行启用。另外还需要设置项目的语言,通过项目-设置-选择语言对进行设置。
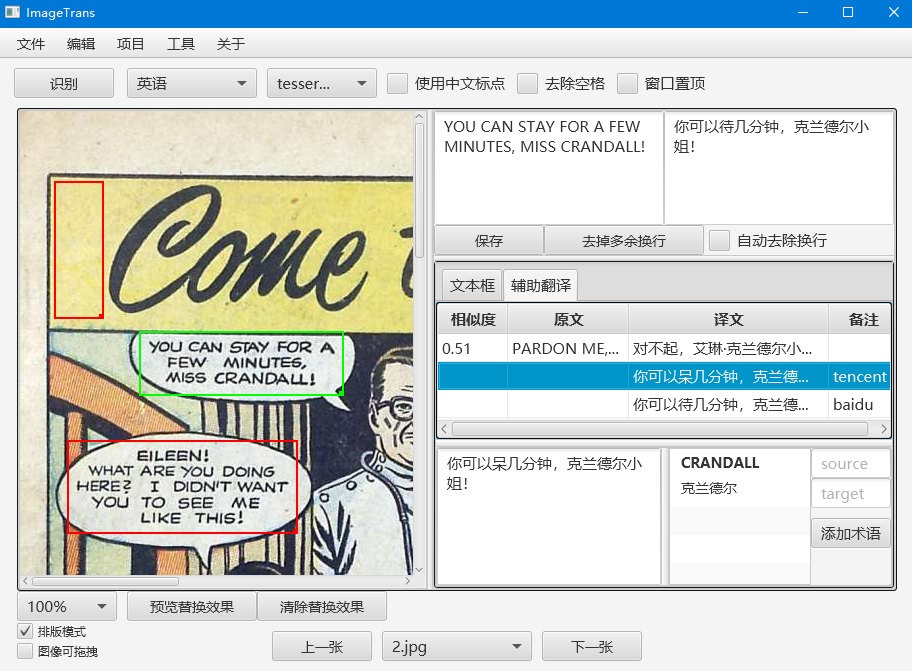
预翻译
点击菜单-项目-批处理-预翻译,可以使用翻译记忆或者机器翻译进行批量翻译。
查看翻译
勾选左下角的查看翻译,可以查看翻译后的图片。精确模式会生成文字掩膜并修复背景,非精确模式则会用背景颜色进行遮盖。
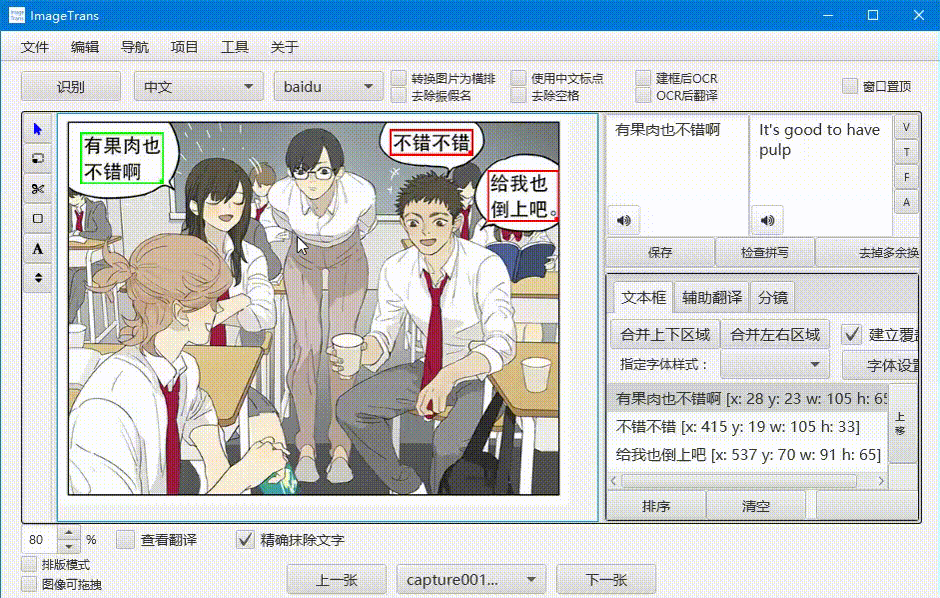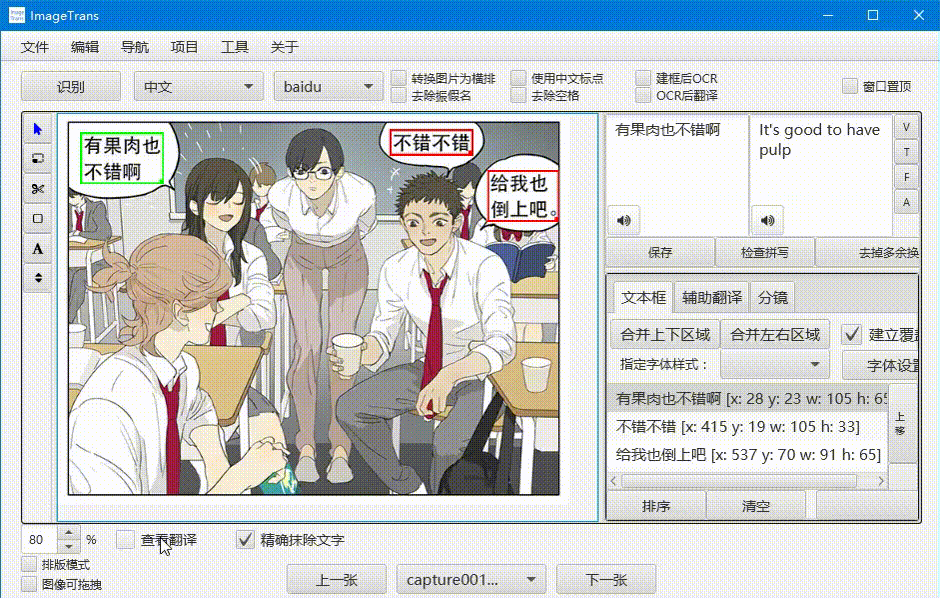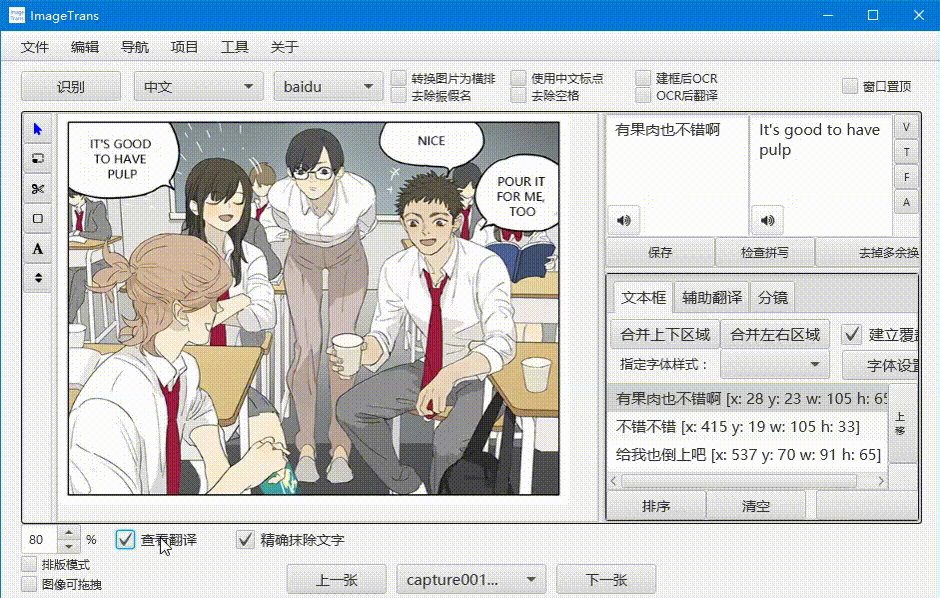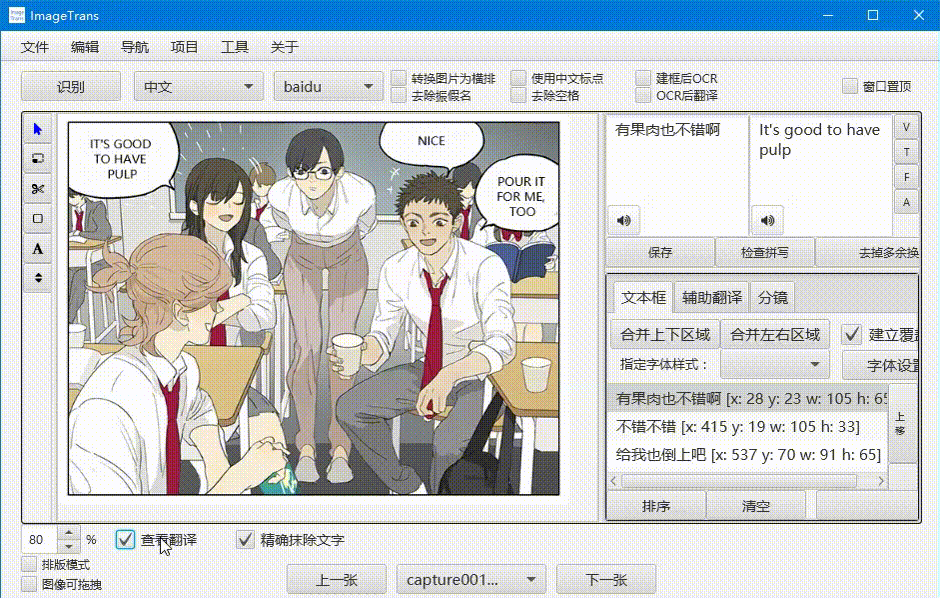
在查看翻译状态下勾选排版模式,译文区域将被框出,并支持调整位置和修改样式。

生成成品图
点击文件-导出当前图片为-JPG,结果将输出在对应图片的文件夹的out文件夹中。选项ORA支持将文件导出为多层图像格式ORA,该格式能保存图层信息,供PS、Gimp和Krita等图像编辑软件编辑。
除此以外,ImageTrans可支持导出PSD。
如果要生成全部图片的成品图,需要通过项目-批处理-导出所有图片的成品图进行操作。
设置文字样式
设置文字样式主要有两个作用,一个是在ImageTrans中使用,一个是用于导出PSD时设置字体。
点击菜单-项目-设置-字体样式可以设置全局样式,设置选项包括使用的字体、文字大小、文字方向、行距、对齐方式、旋转角度、描边等等。
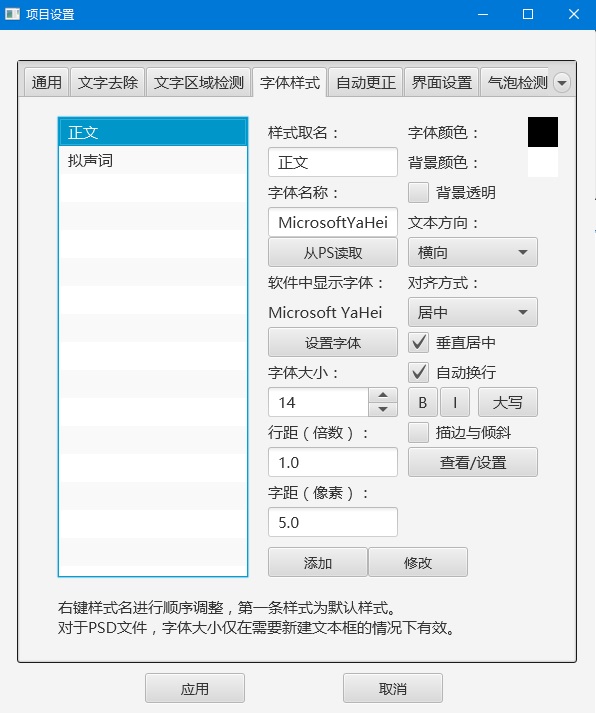
排在第一的样式是默认样式。在样式上方右键可以执行排序和删除操作,在列表的空白处右键可以选择从其它项目导入样式。
设置全局样式后可以给文字区域指定使用哪个样式。
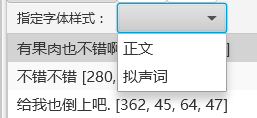
另外也支持设置本地样式。本地样式的优先级大于全局样式。
点击左侧的字体按钮以启用字体设置工具栏,可以便捷地设置本地样式。

也可以通过文字区域列表上方的字体设置进行设置。它有一个专门的界面,能设置描边、旋转、是否启用本地样式。它能调出全局字体样式的设置界面进行更详细的设置(会读取添加在末尾的样式为本地字体样式)。
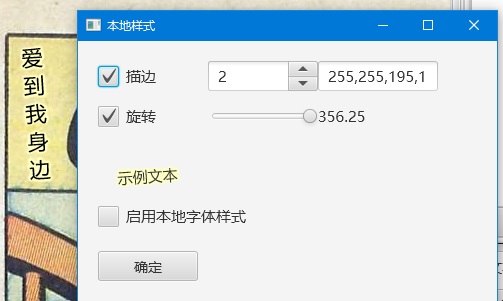
点击左侧的多选按钮以启动多选工具栏,可以调整多个文本框的位置并统一其字体样式。
获取Photoshop用字体名
因为Photoshop需要的字体名比较特殊,需要从PS中获得。方法是在PS中新建一张图片,建立一个文本框,设置所需字体,并完成文字编辑操作,是文本框处于非编辑状态。之后在ImageTrans中点击读取即可。非Windows系统需要使用readFont.jsx脚本。
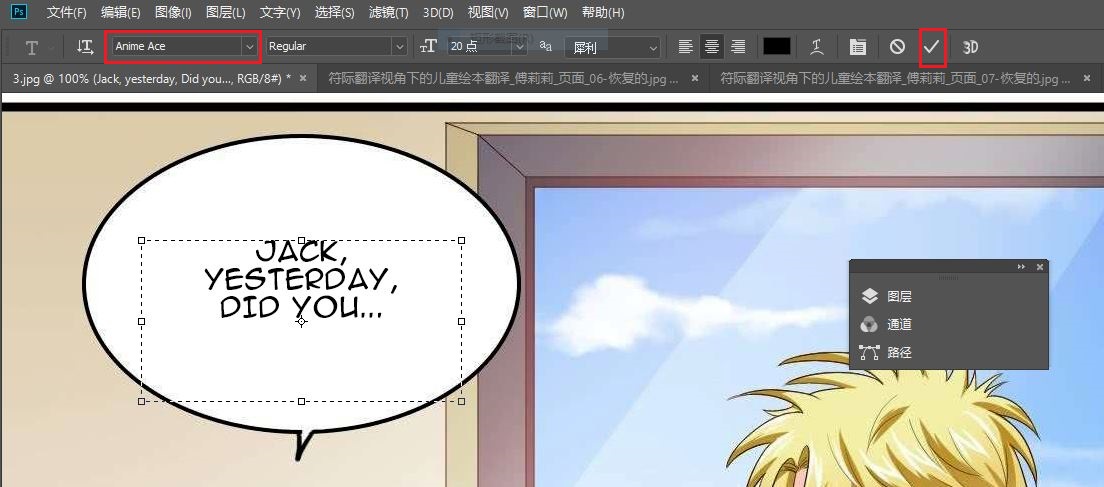
自动调整字体大小
软件默认能根据文字区域大小自动调整字体大小。可以在项目设置中设置是否启用该功能以及最大、最小字体大小。
字体大小的优先级是这样的:
本地样式中的字体大小>自动调整字体大小>全局样式中的字体大小。
富文本
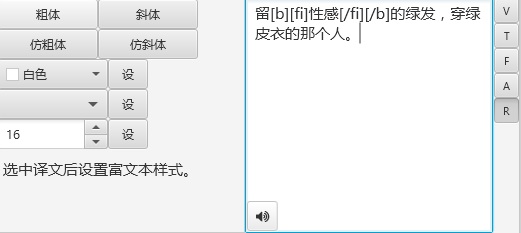
ImageTrans可以使用BBCode来标记富文本格式,比如下图中运用的粗体和斜体。

是使用这样的标记文本表示的: 留[b][fi]性感[/fi][/b]的绿发,穿绿皮衣的那个人。 。
下面是支持的标记说明:
标签名 |
效果 |
用例 |
|---|---|---|
b |
粗体(需要字体本身支持粗体) |
[b]文本[/b] |
i |
斜体(需要字体本身支持斜体) |
[i]文本[/i] |
fb |
仿粗体(仅用于横排) |
[fb]文本[/fb] |
fi |
仿斜体(仅用于横排) |
[fi]文本[/fi] 或者 [fi=2,2,2]文本[/fi] 2,2,2分别代表倾斜程度、纵坐标偏移量和高度偏移量 |
u |
下划线(仅用于横排) |
[u]文本[/u] |
s |
删除线(仅用于横排) |
[s]文本[/s] |
h |
竖排内横排(仅用于竖排) |
[h]文本[/h] |
offsetx |
横向偏移量(仅用于竖排) |
[offsetx=5]文本[/offsetx] |
offsety |
纵向偏移量(仅用于竖排) |
[offsety=5]文本[/offsety] |
fontfamily |
字体名 |
[fontname=Arial]文本[/fontname] |
fontsize |
文字大小 |
[fontsize=32]文本[/fontsize] |
fontcolor |
文字颜色 |
[fontcolor=#FF0000]文本[/fontcolor] |
点编辑区域右侧的按钮R可以启用富文本编辑器,便于快速插入对应的BBCode代码。
批处理
以上对单个图片的操作都可以通过菜单-项目-批处理对所有图片进行操作。可以通过自定义工作流功能一次性对所有图片执行所需的操作。
工具栏
点击程序左侧工具栏按钮,可以切换不同的工具栏。
目前支持以下工具栏:
OCR。
多选。支持选中多个区域并进行对齐、删除、合并、统一字体等操作。
文字区域分割。
快速建框。
字体。
排序。支持检测分镜和在文字区域上显示序号。
原图相关。支持调整译文图层透明度和与原文区域进行对齐。
编辑。支持旋转、翻转等图像编辑操作。