快速入门¶
软件安装¶
Windows完整版解压到任意目录后即可,Mac完整版打开dmg文件安装ImageTrans到应用目录即可。
需要使用Tesseract进行OCR的话请自行下载安装。这里提供一个Windows的绿色版本:百度网盘(提取码:ktpt),下载后将tesseract-ocr目录和ImageTrans放在一起。额外的语言包请放在 tesseract-ocr\tessdata 目录下。
本工具支持的在线OCR和机器翻译服务均需要设置API才能使用,其中云译和ocrspace为免费提供。付费用户还能获得百度和Azure的API。
以下内容是对于跨平台的版本:
下载ImageTrans的压缩包,解压到任意目录,双击ImageTrans.jar或者命令行输入 java -jar ImageTrans.jar 即可运行。
软件依赖JRE 1.8运行环境,请先下载安装:百度网盘(提取码:mhsy)
验证登录¶
每次运行ImageTrans时,会显示验证器,需要填入购买时填写的email和订单号。订单号可以在收到的邮件中找到。
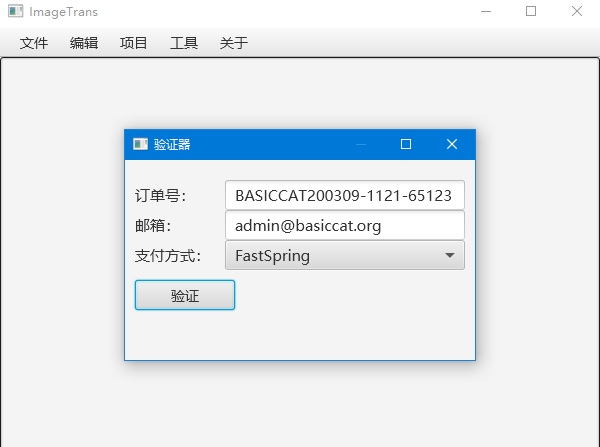
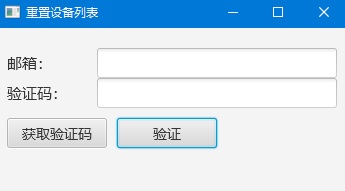
一个email可以在三台设备上使用,要更换设备则需要使用邮箱进行重置。
文字转录¶
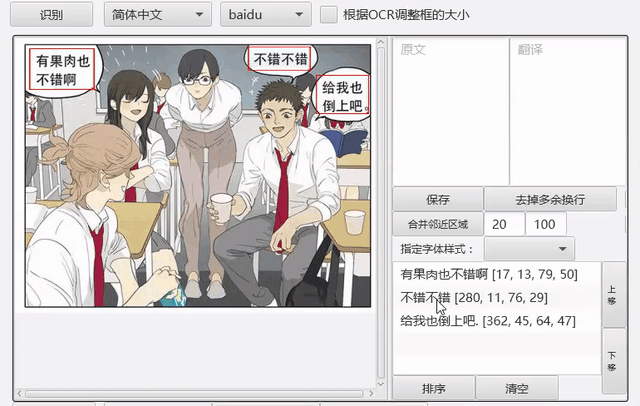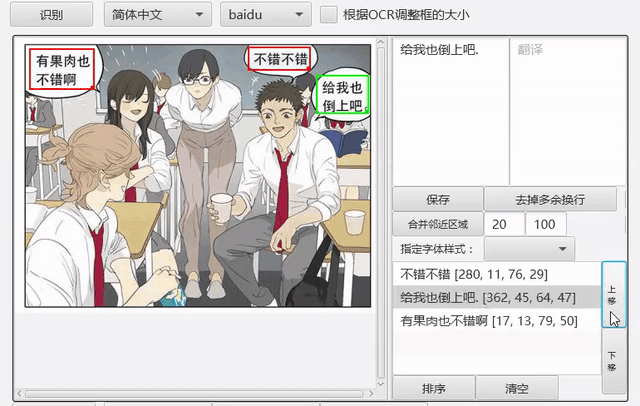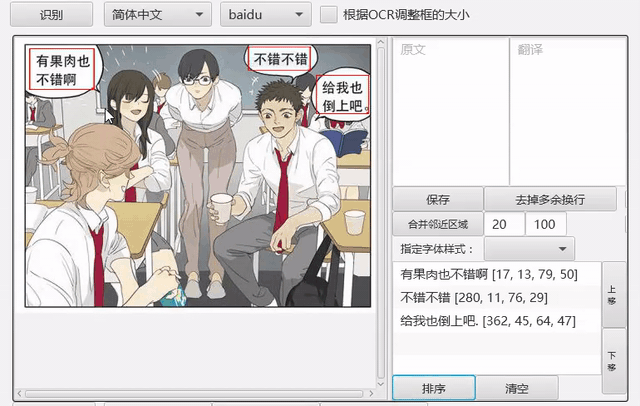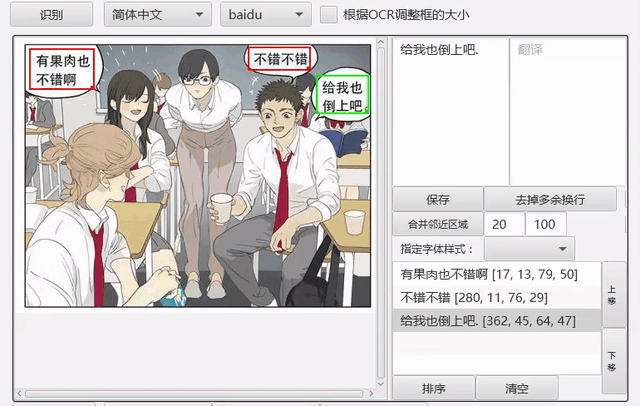
工具支持框选文字区域并识别。
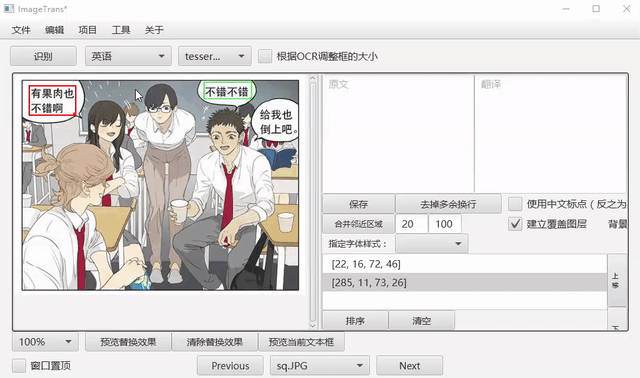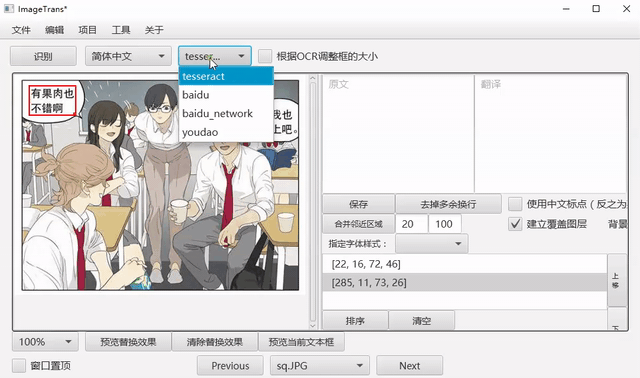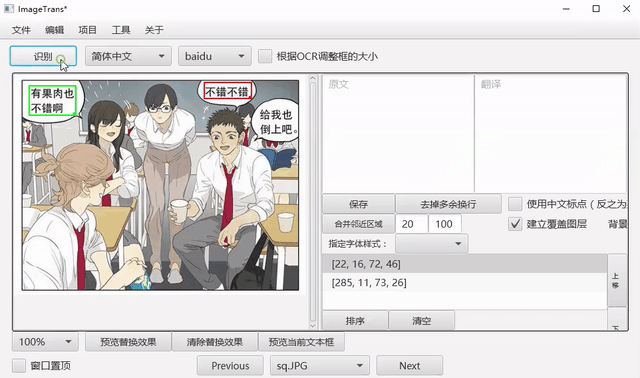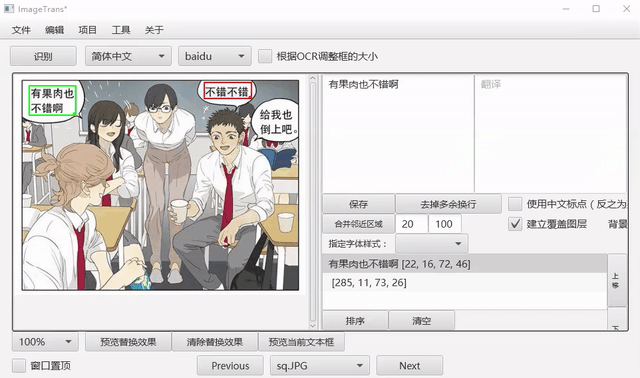
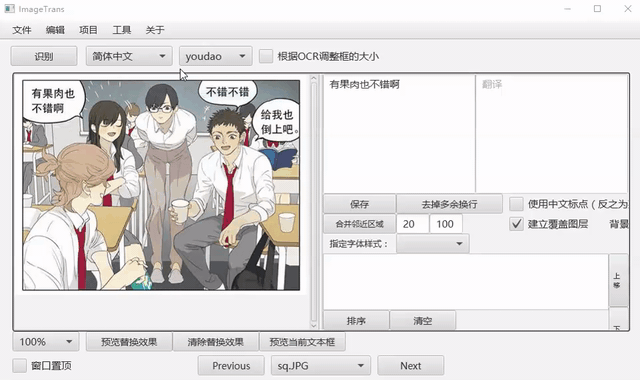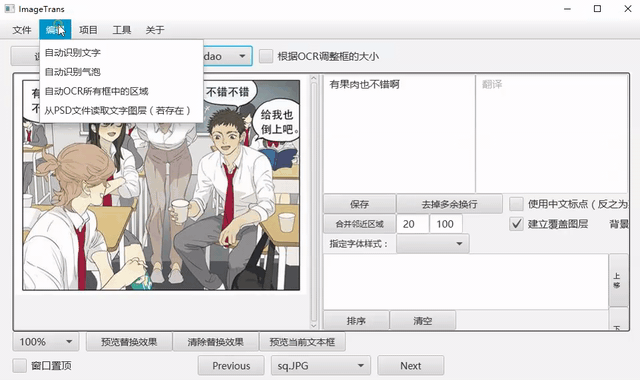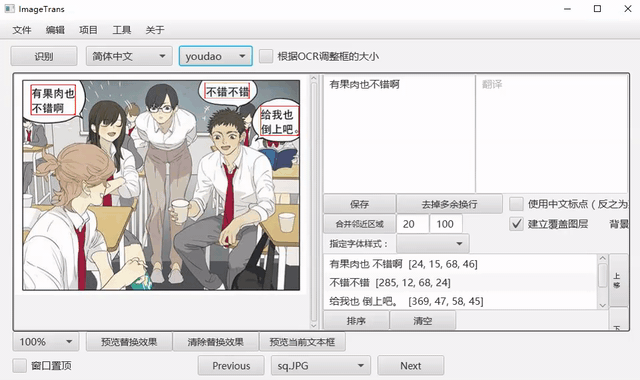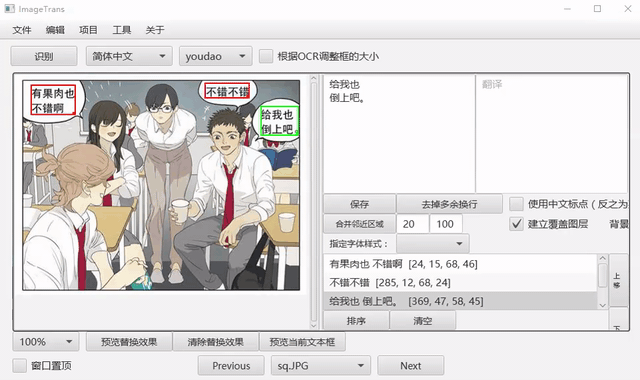
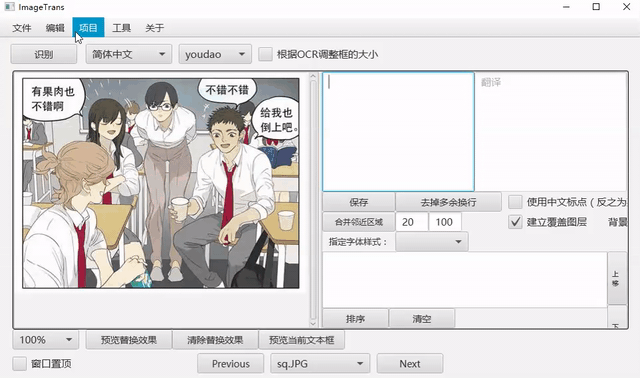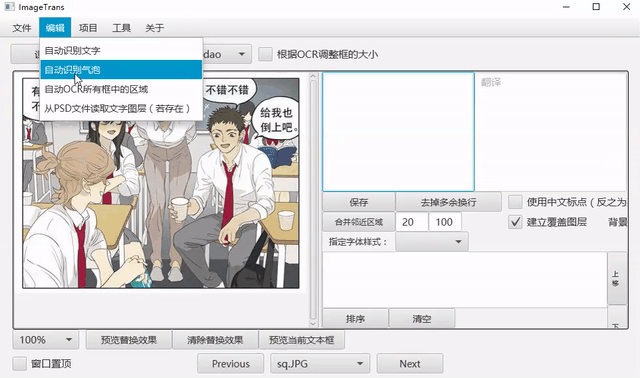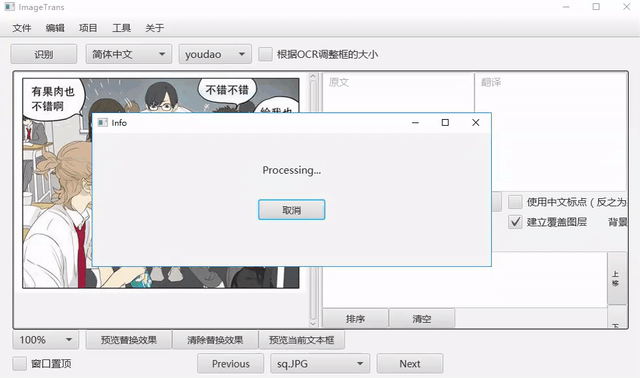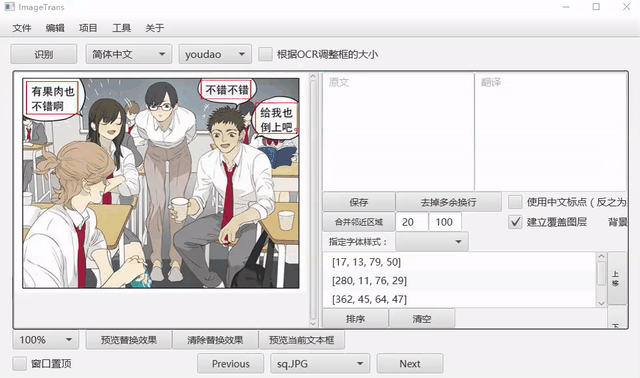
自动OCR所有区域¶
我们可以先把文字区域框出,然后批量进行OCR。点击菜单-编辑-自动OCR所有区域进行操作。
导出¶
导出有多种选项。
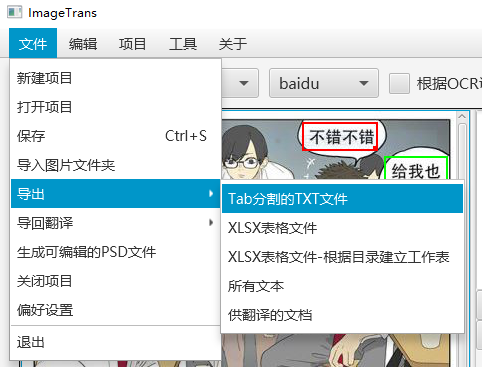
- Tab分割的TXT文档,包含坐标信息、字体样式、文字等信息
- XLSX表格,和TXT的内容一样
- XLSX表格-根据目录建立工作表,按子目录保存图片名、原文和译文信息
- 所有文本,按每张图片生成包含图片文字的txt文档
- 供翻译的文档,将原文和译文信息以表格的形式导出为一个docx文档或者txt文档
翻译¶
在译文区域输入译文并点击保存可以完成一个文字区域的翻译。
可以将翻译导出为docx文档供外部人员翻译,之后再通过菜单-导回翻译-docx文档进行导回。
计算机辅助翻译软件BasicCAT支持直接操作ImageTrans的项目文件进行翻译。
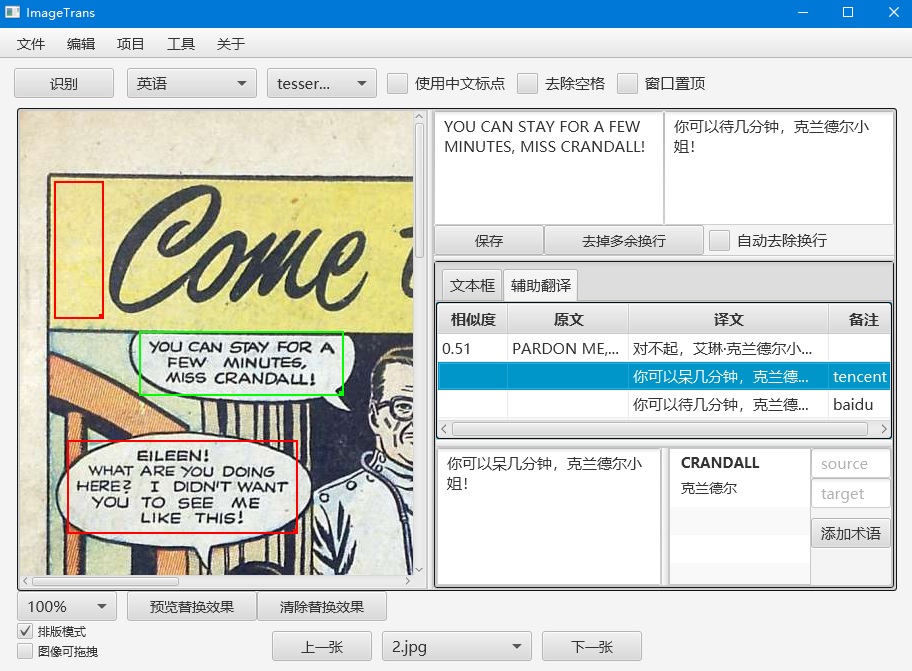
翻译记忆、机器翻译和术语管理¶
切换右侧的操作区到辅助翻译页面,可以使用翻译记忆、机器翻译和术语管理这三个功能。机器翻译需要在偏好设置里设置API,并进行启用。另外还需要设置项目的语言,通过项目-设置-选择语言对进行设置。
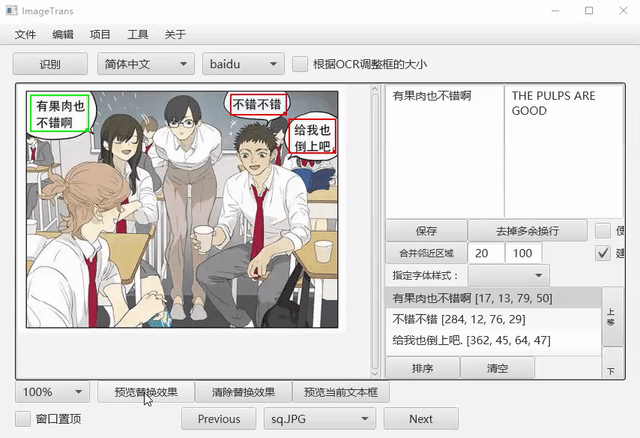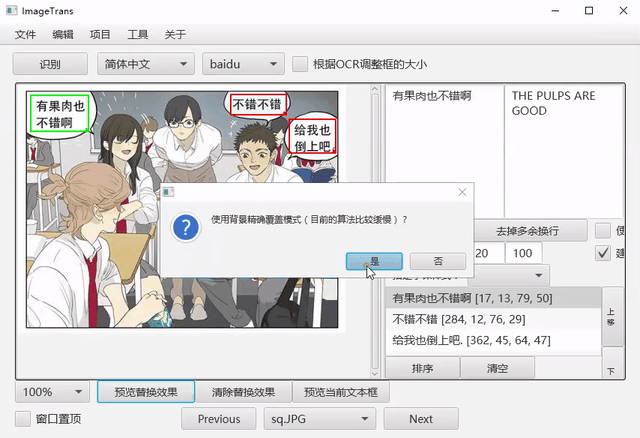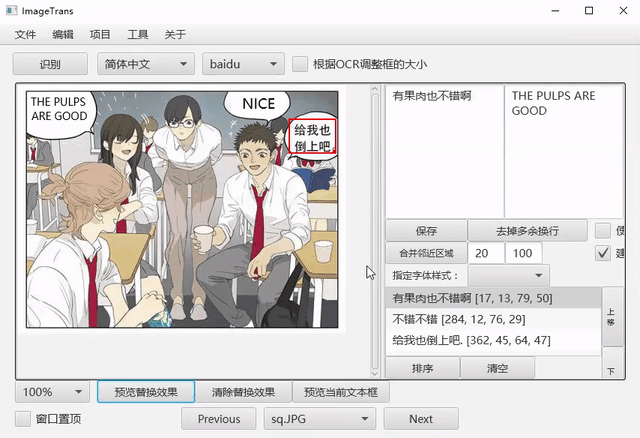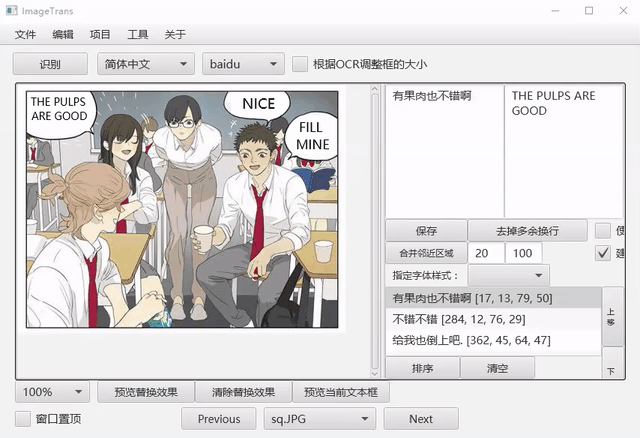

生成成品图¶
首先将图片比例调整为100%,之后点击预览,得到成品图。点击文件-导出当前图片为-JPG,结果将输出在对应图片的文件夹的out文件夹中。另一选项ORA支持将文件导出为多层图像格式ORA,该格式能保存图层信息,供PS、Gimp和Krita等图像编辑软件编辑。
除此以外,ImageTrans可支持导出PSD。
设置文字样式¶
设置文字样式主要有两个作用,一个是在ImageTrans中进行预览,一个是用于导出PSD时设置字体。
点击菜单-项目-设置-字体样式可以进行设置使用的字体、文字大小、行距、对齐方式等等。
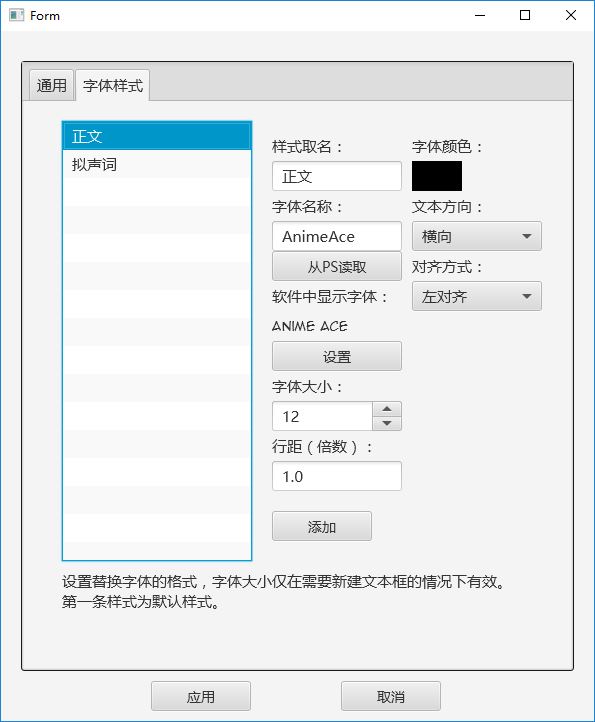
如果要修改某个样式,请点击该样式以加载设置,修改后点击添加,然后删去原来的样式。排在第一的样式是默认样式。
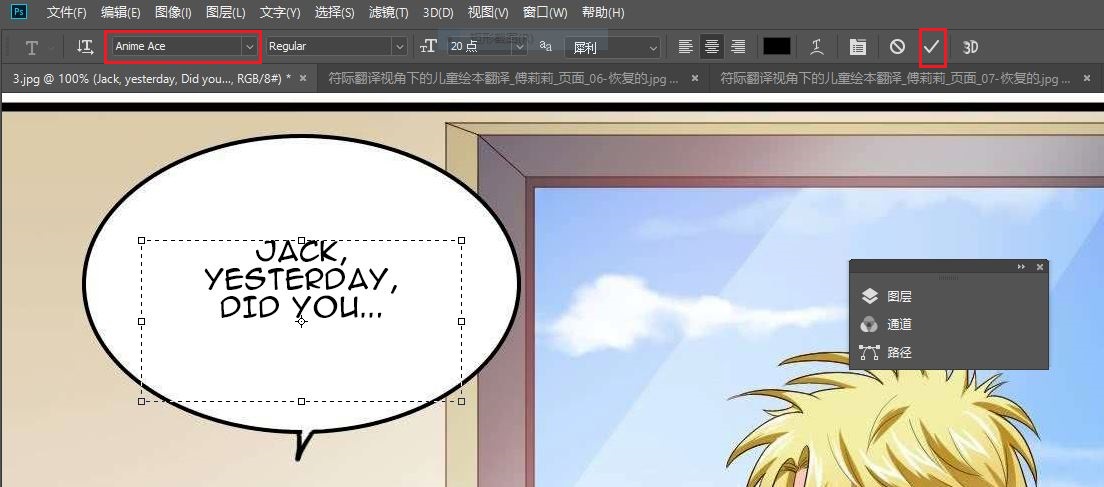
因为Photoshop需要的字体名比较特殊,需要从PS中获得。方法是在PS中新建一张图片,建立一个文本框,设置所需字体,并完成文字编辑操作,是文本框处于非编辑状态。之后在ImageTrans中点击读取即可。非Windows系统需要使用readFont.jsx脚本。
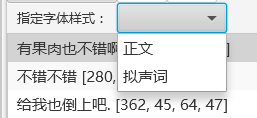
可以给文字区域设置专门的字体样式。
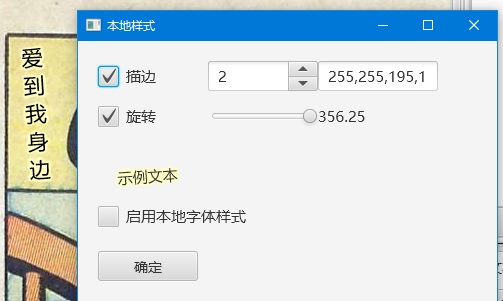
另外也支持设置本地样式,除了全局文字样式包含的内容外,支持描边和旋转角度的设置。设置本地字体样式时会调出全局字体样式的设置界面,默认读取添加在末尾的样式为本地字体样式。
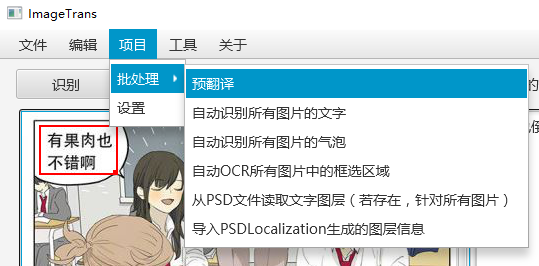
批处理¶
以上对单个图片的操作都可以通过菜单-项目-批处理对所有图片进行操作。